






什么是Spark实时流关联
随着大数据技术的不断发展,实时数据处理已经成为企业级应用中不可或缺的一部分。Spark作为一款高性能的大数据处理框架,其实时流处理能力尤为突出。Spark实时流关联,即Spark Streaming对实时数据流进行关联操作,是实现实时数据处理的关键技术之一。
Spark Streaming简介
Spark Streaming是Apache Spark的一个扩展模块,用于处理实时数据流。它允许用户以高吞吐量和低延迟处理实时数据,同时与Spark的其他模块(如Spark SQL、MLlib等)无缝集成。Spark Streaming支持多种数据源,包括Kafka、Flume、Twitter等,并且能够处理各种类型的数据,如图像、视频、文本等。
实时流关联的背景
在现实世界中,许多应用场景需要实时处理多个数据流,并将它们关联起来进行分析。例如,电商网站需要实时分析用户在购物车中的行为和购买历史,以便进行精准营销;金融行业需要实时监控交易数据,以发现异常交易行为。这些场景都需要实时流关联技术来实现。
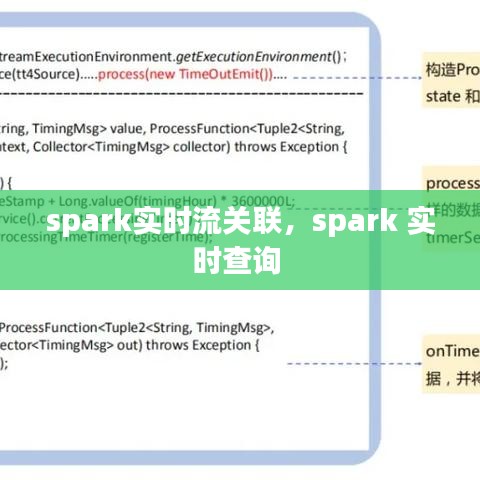
Spark实时流关联的实现原理
Spark实时流关联的实现主要依赖于Spark Streaming中的DStream(Discretized Stream)抽象。DStream是Spark Streaming对实时数据流的一种抽象表示,它将实时数据流划分为一系列连续的小批量数据(batch),然后对每个批次的数据进行处理。
在Spark Streaming中,实时流关联可以通过以下步骤实现:
- 创建两个或多个DStream,分别代表需要关联的实时数据流。
- 使用DStream的transform操作或updateStateByKey操作,对其中一个或多个DStream进行转换,以便与另一个DStream进行关联。
- 使用DStream的join、union或window操作,将转换后的DStream与其他DStream进行关联。
- 对关联后的数据流进行进一步的处理和分析。
Spark实时流关联的实践案例
以下是一个简单的Spark实时流关联的实践案例,假设我们需要将用户在电商网站上的浏览记录和购买记录进行关联,以分析用户的购买行为。
- 创建两个DStream,分别代表浏览记录和购买记录。
- 对浏览记录DStream进行转换,提取用户ID和时间戳信息。
- 对购买记录DStream进行转换,提取用户ID和时间戳信息。
- 使用DStream的join操作,将两个转换后的DStream按照用户ID和时间戳进行关联。
- 对关联后的数据流进行分析,例如计算每个用户的浏览和购买次数、购买频率等。
Spark实时流关联的优势
Spark实时流关联具有以下优势:
- 高性能:Spark Streaming基于Spark的核心计算引擎,能够提供高性能的实时数据处理能力。
- 易用性:Spark Streaming提供了丰富的API,使得用户可以轻松实现实时流关联操作。
- 可扩展性:Spark Streaming支持水平扩展,能够处理大规模的实时数据流。
- 集成性:Spark Streaming可以与Spark的其他模块无缝集成,实现复杂的数据处理和分析。
总结
Spark实时流关联是大数据时代实时数据处理的重要技术之一。通过Spark Streaming的实时流关联功能,用户可以轻松地将多个实时数据流进行关联,实现复杂的数据分析和处理。随着大数据技术的不断发展,Spark实时流关联将在更多领域得到应用,为企业提供更加智能化的实时数据处理解决方案。
转载请注明来自大成醉串串企业,本文标题:《spark实时流关联,spark 实时查询 》






 蜀ICP备2020032544号-3
蜀ICP备2020032544号-3