






什么是Storm Kafka实时计算
Storm Kafka实时计算是一种结合了Apache Storm和Apache Kafka的分布式流处理技术。Apache Storm是一个开源的分布式实时计算系统,它能够对大量数据进行实时处理,而Apache Kafka则是一个分布式流处理平台,能够处理高吞吐量的数据流。将两者结合使用,可以实现从数据源到处理结果的实时数据流处理。
Storm Kafka的优势
使用Storm Kafka进行实时计算具有以下优势:
高吞吐量:Kafka能够处理高吞吐量的数据流,而Storm则能够对这些数据进行实时处理,确保系统的整体性能。
容错性:Kafka和Storm都是分布式系统,具有高可用性和容错性,能够在节点故障时自动恢复。
可扩展性:两者都支持水平扩展,可以根据需求增加更多的节点来提高系统的处理能力。
灵活的数据处理:Storm提供了丰富的处理组件,可以满足各种数据处理需求,而Kafka则支持多种数据格式,方便数据的传输和存储。
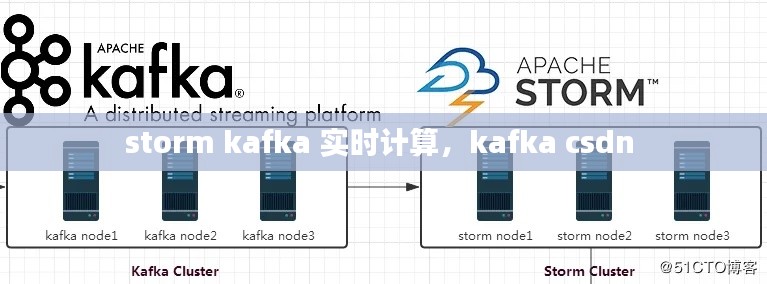
Storm Kafka的架构
Storm Kafka的架构主要包括以下几个部分:
数据源:可以是Kafka集群中的主题(Topic),也可以是其他数据源,如数据库、文件系统等。
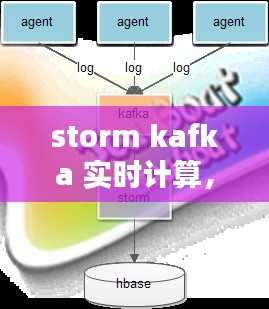
Spout:Spout是Storm中的数据源组件,用于从数据源中读取数据,并将其发送到Storm拓扑中。
Bolt:Bolt是Storm中的处理组件,用于对Spout发送来的数据进行处理,如过滤、转换、聚合等。
Storm拓扑:拓扑是Storm中的数据处理流程,由Spout和Bolt组成,可以包含多个处理阶段。
消息队列:Kafka作为消息队列,负责存储和转发Spout和Bolt之间的消息。
Storm Kafka的应用场景
Storm Kafka在以下场景中具有广泛的应用:
实时推荐系统:通过实时分析用户行为数据,为用户提供个性化的推荐内容。
实时监控:实时监控网络流量、服务器性能等指标,及时发现并处理异常情况。
实时广告投放:根据用户实时行为,动态调整广告投放策略,提高广告效果。
实时数据分析:对实时数据进行实时分析,为业务决策提供支持。
Storm Kafka的配置与优化
为了确保Storm Kafka的性能和稳定性,以下是一些配置和优化建议:
合理配置Kafka的副本因子和分区数,以提高系统的容错性和吞吐量。
根据实际需求调整Storm拓扑的并行度,以充分利用资源。

优化Spout和Bolt的处理逻辑,减少数据传输和计算开销。
监控系统的性能指标,及时发现并解决潜在问题。
总结
Storm Kafka实时计算是一种高效、可靠的数据处理技术,能够满足现代大数据时代对实时数据处理的需求。通过结合Kafka和Storm的优势,可以构建出高性能、可扩展的实时数据处理系统,为各种业务场景提供强大的支持。
转载请注明来自大成醉串串企业,本文标题:《storm kafka 实时计算,kafka csdn 》





 蜀ICP备2020032544号-3
蜀ICP备2020032544号-3