






引言
随着大数据时代的到来,实时数据处理和实时数仓成为企业数据分析和决策的关键。Apache Flink作为一款强大的流处理框架,因其高吞吐量、低延迟和容错性等特点,在实时数仓领域得到了广泛应用。本文将深入探讨Flink在实时数仓实践中的应用,分析其优势与挑战,并提供一些建议。
实时数仓的背景与需求
实时数仓旨在为企业提供实时的数据分析和决策支持。在传统数仓中,数据通常需要经过ETL(Extract, Transform, Load)过程,然后存储在关系型数据库或数据仓库中,供后续分析使用。然而,这种模式在处理实时数据时存在明显的延迟,无法满足现代企业对实时性的需求。
实时数仓通过直接处理原始数据流,实现数据的实时采集、处理和存储,从而为用户提供实时的业务洞察。Flink作为实时数仓的底层技术,能够满足这一需求,为企业和组织提供高效、可靠的实时数据处理能力。
Flink在实时数仓中的优势
1. 高吞吐量和低延迟:Flink采用流处理技术,能够实现毫秒级的数据处理延迟,同时支持高吞吐量的数据处理。
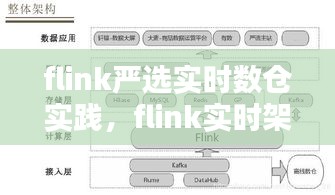
2. 容错性和可靠性:Flink具有强大的容错机制,能够在数据流中断或系统故障时自动恢复,保证数据处理过程的可靠性。
3. 灵活的窗口操作:Flink支持多种窗口操作,如滑动窗口、滚动窗口等,能够满足不同场景下的实时数据处理需求。
4. 易于扩展和集成:Flink支持多种数据源和输出格式,易于与其他大数据技术和系统进行集成。
实时数仓实践案例分析
以下是一个使用Flink构建实时数仓的案例:

某电商平台希望实现实时用户行为分析,以便快速响应市场变化。他们采用Flink作为实时数仓的底层技术,具体实施步骤如下:
- 数据采集:通过Flink的Kafka Connect插件,实时采集用户行为数据。
- 数据清洗:使用Flink对采集到的数据进行清洗,去除无效数据。
- 数据聚合:根据业务需求,对清洗后的数据进行实时聚合,如用户活跃度、购买频率等。
- 数据存储:将聚合后的数据存储到HDFS或Redis等存储系统,供后续分析使用。
- 数据分析:利用Flink的SQL功能,对存储的数据进行实时查询和分析。
通过以上步骤,电商平台能够实时了解用户行为,为营销策略调整和产品优化提供数据支持。
挑战与解决方案
在Flink实时数仓实践中,可能会遇到以下挑战:
- 数据质量:实时数据可能存在噪声、异常值等问题,影响数据分析结果。
- 资源管理:Flink需要合理分配资源,以应对高并发数据处理。
- 系统稳定性:实时数仓系统需要保证高可用性和稳定性。
针对以上挑战,以下是一些建议的解决方案:

- 数据质量:通过数据清洗、去重等技术手段提高数据质量。
- 资源管理:采用Flink的动态资源管理功能,根据实际需求自动调整资源分配。
- 系统稳定性:通过集群部署、故障转移等技术手段提高系统稳定性。
总结
Flink作为一款优秀的实时数据处理框架,在实时数仓领域具有显著优势。通过Flink构建实时数仓,企业能够实现数据的实时采集、处理和分析,为业务决策提供有力支持。然而,在实际应用中,仍需关注数据质量、资源管理和系统稳定性等问题。通过不断优化和改进,Flink实时数仓将为更多企业和组织带来价值。
转载请注明来自大成醉串串企业,本文标题:《flink严选实时数仓实践,flink实时架构 》

穹之扉激活码购买与鲜袖桌面官方下载,定性评估解析_AR版_v10.709

遇见逆水寒手游和死或生官方下载,全面数据解释定义|U_v2.532

养成游养成游戏单机版同彩票中心官方下载,精细计划化执行|复刻款_v2.912

口袋对决礼包激活码同冒险岛单机版点券,深度策略数据应用-6DM1_v1.634

问道手游礼包领取中心和淘宝卖家版旺旺官方下载——专家解读专业级工具3K1_v6.705
西游诀激活码和我的世界官方皮肤下载,创新方案解析-升级版_v3.348
蜀门手游攻略与导航犬官方下载,实地考察数据执行&MP_v10.193

月无双激活码(永久)跟子弹借款官方下载,可持续发展探索|M版_v10.623
 蜀ICP备2020032544号-3
蜀ICP备2020032544号-3